SETOL-based LLM Mechanistic Interpretability of Domain Knowledge

In this ongoing research study, we collaborate with WeightWatcher to build a new LLM mechanistic interpretability framework grounded in the SETOL (Semi-Empirical Theory of Deep Learning) perspective. This exploration aims to combine insights from spectral analysis of weights with energy-based and physics-inspired approaches to understanding how large language models (LLMs) process information regarding a domain-specific extraction objective.
Background and Motivation
SETOL in a Nutshell
SETOL proposes that deep learning can be understood and directly evaluated in the latent domain (without data) via tools from statistical mechanics, notably spectral analysis of weight matrices (eigenvalue densities, singular value distributions, etc.). By focusing on the emergent properties of weights rather than specific architectural details, SETOL offers a unifying lens for phenomena like effective rank, power-law distributions, and layer-wise “energy” contributions.
Why Mechanistic Interpretability?
Mechanistic interpretability attempts to reveal how internal components (layers, attention heads, neuron activations) work together to produce model outputs. Traditional interpretability tools often:
- Provide visualizations of activations.
- Probe attention patterns or saliency maps.
- Evaluate component knockouts to see how model predictions change.
However, truly mechanistic approaches delve deeper, aiming to reverse-engineer the transformations happening inside. Our hope is to integrate WeightWatcher’s spectral insights into this process bridging low-level matrix analysis with a broader understanding of an LLM’s “energy landscape”.
Overview
1. WeightWatcher’s Role
- Layer-Wise Analysis: WW computes power-law exponents and spectral entropies on the weight matrices of each layer.
- Energy Landscapes: A major interest is to interpret these spectral metrics in terms of an “energy” function that relates to training stability, generalization, and potential phase transitions.
2. Mechanistic Interpretation
- Activation Traces: We aim to explore ways to capture activation statistics (e.g., from self-attention blocks, feed-forward layers) in tandem with weight spectral metrics.
- Cross-Layer Interactions: Investigating whether “dominant spectral components” at layer ( L ) align with “attention heads” or “key–query–value transformations” in layer ( L+1 ).
3. SETOL’s Theoretical Guidance
- Semi-Empirical: While the theory is grounded in statistical mechanics, it leaves room for empirical discoveries specific to deep networks.
- Extended Wick’s Theorem: A recurring idea is to see if certain expansions or transformations (akin to Wick’s theorem in field theory) can approximate cross-layer interactions in large-scale architectures like LLMs.
Research Goals
- Energy Landscape of Activations
- Move beyond analyzing just weight matrices to also study activations and attention patterns as part of an energy or free-energy landscape.
- Spectral Overlaps & Domain-Specific Knowledge
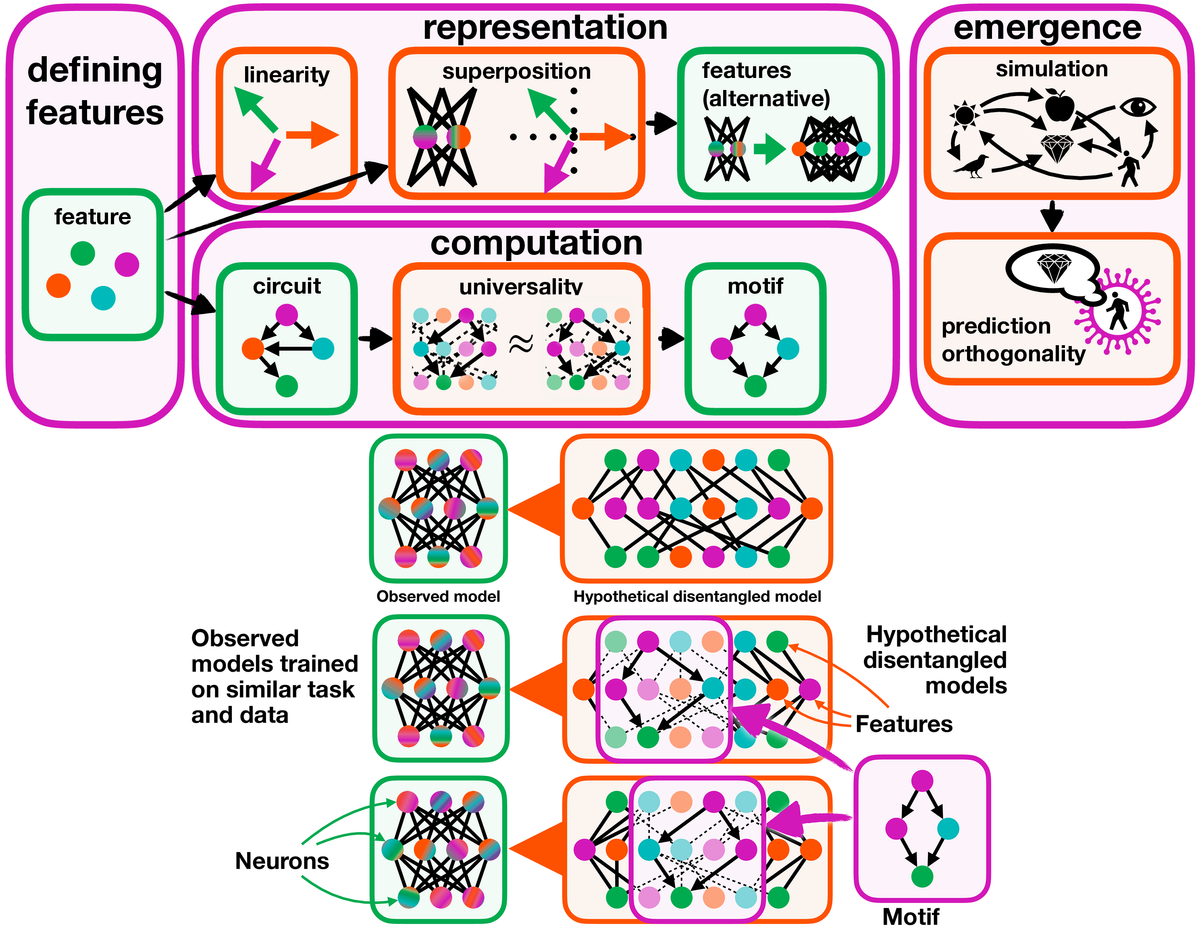
- Investigate how domain-specific “circuits” or knowledge might manifest as distinctive spectral features in the weight or activation space.
- Potentially leverage mechanistic interpretability methods (e.g., knowledge circuits, domain mapping) to see if certain singular values or eigenmodes align with domain knowledge.
- Layer-Layer Correlation
- Explore cross-layer interactions with a focus on entropic or information-theoretic metrics, evaluating how these propagate or attenuate through the model.
- Scalability
- Develop toolchains that can scale to modern LLMs, without requiring prohibitively large matrix decompositions or memory usage.
Proposed Approach
- Dual Analysis:
- Weight Spectra using WeightWatcher.
- Activation Traces during inference or training steps (collected via instrumentation libraries).
- Energy-Based Perspective:
- Attempt to define an effective “energy” measure for activation distributions (energy landscapes).
- Compare/contrast it with the “energy” derived from weight spectral norms or exponents.
- Mechanistic Probing:
- Use existing interpretability approaches (e.g., attention lens, residual stream analysis, knowledge circuits) to label or group certain transformations as belonging to domain-specific reasoning.
- Correlate these groupings with dominant singular vectors or spectral entropies from WeightWatcher’s analysis.
- Semi-Empirical Validation:
- Conduct small-scale experiments to confirm if changes in spectral measures align with changes in interpretability insights (e.g., flipping a key attention head vs. removing a principal component).
- Evaluate how “energy-based interpretability” compares to standard feature-attribution metrics.
Potential Impact
- Better Understanding of LLM Internals: Revealing how LLMs structure knowledge in weights and activations can guide robustness improvements and trustworthy AI metrics for domain-specific data.
- Tooling Synergy: Extending WeightWatcher to activation-level analysis opens new avenues for advanced debugging, “layer pruning,” and diagnosing “superposition” phenomena in LLMs.
- Physics-Inspired AI: Progress on energy-based frameworks in large-scale models could shape next-generation interpretability, bridging the gap between theoretical physics and practical machine learning.
Conclusion
This research marks a step towards a unified, physics-inspired framework for deep learning. By unifying the spectral viewpoint of SETOL with practical interpretability techniques, we aim to unveil how large language models organize, store, and transform knowledge in their layers and activations for domain-specific data.
Stay tuned for more updates as we experiment with real LLMs, refine the notion of an activation-level energy, and see how it dovetails with the weight-based perspective to deepen our understanding of modern AI systems.